-

-
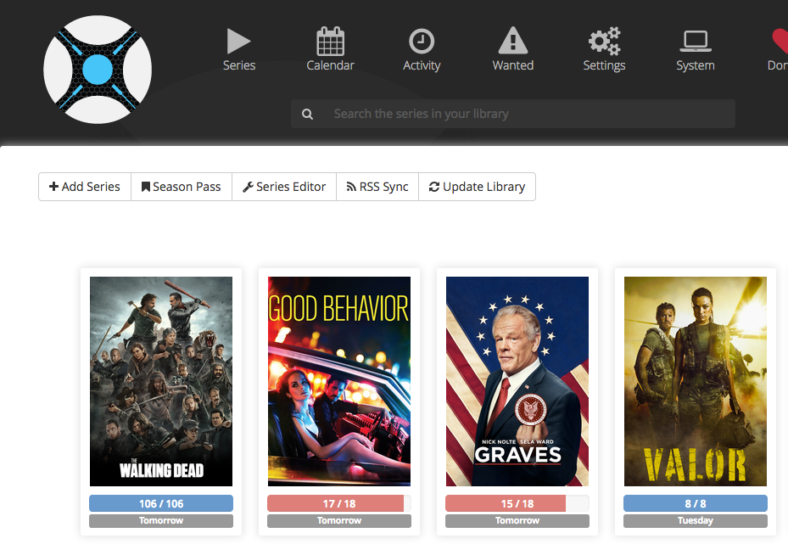
Empty emergency seat because KLM wants money for that!
-

-
How can somebody sit on this toilett?
-

-
Dangerous Victorinox Swiss Card
My recent business trip to China is over and I disappointed me so much that I need to write down my experience.
Actually I was looking forward to my trip, since I decided to choose some other airline then Turkish, which are great, but right now I’m a bit too afraid to travel over Istanbul. As always my company only pays travels in economy class, which are quite painful on long-haul flights of +11 hours. So we looked at some offers and I decided that the combination of traveling eastbound with Air France and westbound with KLM looked most promising. Finally, I can fly on an Airbus 380 and on the way back take maybe one of the last times the old lady, the Boing 747.
ZRH-CDG-PVG
I’m aware that you can always pay a surcharge to get a preferred seat. So when the online check-in opened I payed some extra money from my pocket to get a better seat in the Airbus 380. For the short trip from Zurich to Paris, I did not bother.
I arrived on time at the airport and checked in. What I realised, was the they were particularly paying attention about the weight of my hand luggage. But since my suitcase was 10 kilos below the max, they accepted a 2 kilos plus on my hand luggage. How nice of the check-in crew. But to move 2 kilos to my main luggage would also not have been a problem. I rushed to the gate and had some dinner at the airport. So far so good.
Unfortunately, at one point the same lady from the check-in – now working at the gate – informed all the guests, that the plane would have about 20 min delay since late arrival of the previous flight, but all connection flight still could be made. I’ve got a quite positive attitude, but that made me already a bit nervous. The plane left Zurich about 20 to 30 minutes to late, but I was still early enough to catch my connection flight. Just before landing I spoke to the flight attendant and she confirmed that we still would be able to catch the flight and somebody would be waiting at the gate and accompany us to our gate. So far so good, again. We landed and taxied to the Gate, where the plain suddenly stopped. After standing 5 minutes on the same spot, the captain informed us, that we could not get to the gate, because another airplane would still be there. I started to worry and also questioned myself why a plain was on our spot, since this spot should have been empty for at least 30 minutes and why there are no other gates available. After 15 to 20 minutes, I did not time it exactly to other plain left and we could finally get to the finger dock.
Of course when I disembarked the airplane, there was nobody waiting for us. So all long-haul passengers started to run down the unbelievable long corridors trying to get the flight.
When I finally arrived at the gate, I could see my Airbus 380 still docked. But the French ground crew told me that the boarding was finished and I could not enter the plain anymore. F*%@! They just mentioned that I could anyway not have boarded the flight, since my luggage did not make it. C’mon you can take someone else for a ride, since when is every luggage going together with the owner? Or what happens with lost luggage? Anyway, the crew walked with us to the transfer desk in a speed of a turtle. Once I arrived there, I got a voucher for the IBIS Hotel at the airport. Since I was running almost through half of the airport, I ask how I could get my luggage to grab some fresh clothes. The ground crew answered to me very unsympathetic that the luggage could not be retrieved since the people responsible for this already stopped working. Gimme a break: It was around 23:30 and not 2 o’clock in the night. I only got an overnight box with some sanitary products and a white t-shirt in a lousy quality. The t-shirt was see through so cheap fabric was used and could only be used as a pyjama top. Thankful I’ve had my medication in my hand luggage. They offered some food, but as it was not ready and I would have had to wait for it, so I gratefully rejected it. Air France also told me, that I was already booked on the next flight the next day. So instead of arriving on Monday afternoon and just getting to the hotel to sleep and start my meetings on Tuesday. I would arrive on Tuesday morning, stinking und tired and had to drive directly to work to be able to start meetings after the lunch break. Needless to say all the troubles with rebooking drivers, hotels and meetings. Of course there were no more preferred seats available and to get my money back and also to get compensation, I would need to fill out a form on the Air France website.
The way out of the terminal and to the hotel at the next terminal took more that 30 minutes. I felt like in a labyrinth. I arrived at 00:05 at the Hotel, what was ok, then the voucher was only valid after 00:00 o’clock. I think the airline get then better rates… But at this time all the restaurants or bars where closed. The hotel room has another story to tell. I did not expect much from a worn down IBIS airport hotel. Living from stranded guests, the standards have not to be high to get customers… One thing I need to mention. The toilet! I don’t know what kind of stuff the architect or the sanitary planners have smoked, but how should you be able to sit on the toilet if it’s mounted next to a bent wall. Getting narrower at the front. Hotel guests have to sit in a 45° angle on the toilet which is very uncomfortable since my but is designed symmetrically and has no 45° offset. After a pretty unspectacular night, I had breakfast a little bit late, but still one hour before closing. But a lot of the products had gone, empty bowels were missing and the mess on the table showed that many people had missed some connection flights. But I also survived this and for the emergency I had some “Imodium” with me. I just did not expect to maybe have to use it in Europe…
I also had the time to fill out the web form on the Air France website and I must say Air France does the best to make it as difficult as possible to find the information about compensation. Just “easy” enough that you can not say that it is intentional so difficult to find. But elderly people would have had no chance. So I’m asking for 600€ compensation (as the EU regulations say) and the 44 CHF for the preferred seat.
Finally, I got back to the airport and went to the pass control or better to say to the hand luggage checker before it. They wanted to weight my hand luggage and told me it was to heavy and I had to put it on the plain. Only after I insisted, asking for the manager and told them that it was ok in Zurich, since my other luggage was 10kg below the allow maximal weight, and I was forced to leave the airport since Air France had some operational problems, I could enter the passport control with the 14 kg of hand luggage .
The flight then was ok, when you like to be in a tin can. It was not more an Airbus 380, but a Boing 777. The ratings at SeatGuru.com for the 777 were not brilliant. The inflight entertainment program was not overwhelming, but I also could watch some French classic movies with J.-P. Belmondo from my childhood. What Air France did really well is the safety instruction movie. If you don’t know it, watch in on YouTube. Best so far. I also would recommend the Air France management to travel a long-distance-flight in economy class. But not in a brand new plane, instead in a nicely used configuration. I bet you would feel the same pain on your but, as we all do, because the seats are worn out and you can feel some metal bars. Sitting and sleeping in this chair for over 11 hours is torture.
So finally I arrived in China and even my luggage arrived.
PVG-AMS-ZRH
New airline, new luck. Nope.
It started already when I tried to check-in online around 23 hours before the flight. The best upgrades were already gone. So the only two premium seats available were at an emergency exit. So I reserved one of those and proceeded to the check-out to pay for it. Unfortunately, the booking system had an error and could not process my booking or the chance of the seat. I was sitting in a middle seat on the side, actually 37J. A nightmare and I was not looking forward to my flight. After my terrible experience with Air France I had now some troubles again, even before the journey started. I don’t know if I have to blame KLM for the problems or the Chinese firewall, but the online check-in didn’t work properly.
Arriving at the airport, of course all preferred seats had gone. What else was I to expect? Also to mention is that KLM is leaving at Terminal 1 at Pudong Airport. That’s the creepy pre-version of the developed Terminal 2. So after going through multiple security checks (my luggage got scanned 3 times) and about 10 wipes for explosive material. I got to the gates of Terminal 1. My plan was to diner there since my flight would only leave in about 3 hours. Well that’s what I normally do in Terminal 2. But you can only diner, if you can find food you like or restaurants which do not look like food poisoning. It looked as from this terminal only some local flights to Macao, Korea and other small Asian countries left and of course KLM to Amsterdam. This is why the food was so lousy. Maybe they had no space for a 747 on Terminal 2. I will never find out. At the end I got an overpriced and slightly burned sandwich and a mineral water. And no, Starbuck is not a restaurant, it’s a coffee shop. So they do not count! The last security control actually confiscated my Victorinox Swiss Card which I have with me since 10 years. Also a few times before to China in my hand luggage. Now they decided that a knife with a 2 cm blade and a scissor with even a shorter blade was a risk for the safety. They told me that I could go back to the check-in and put it in the normal luggage. But since my luggage was already checked-in, it would have meant to be in a second luggage for a nice surcharge…
Back to the boarding process. When boarding the plane, the ticket got controlled 3 times on 3 different check-points. Well it looks like the over 1 billion Chinese need to be occupied.
Finally I sat in the airplane. Seat 37J, in-between two other adults. Then the next shock. The seat was even worse than the one at Air France. Really worn out. By the way KLM, if you wonder which plane it was, it was the “Hongkong”. Here the same advice for the management. Fly 11 hours in economy class and you will learn what agony is. The seat also did not get back to the upright position itself after pressing the button on the armrest. You had to pull it back. That’s how worn our this seats are. The next surprise was the electronic box for the entertainment system which was placed unter the middle seat in front of me. So off we go with another 5 cm of my legspace.
I touched the screen of the entertainment system and nothing happens. Until I found out this was no touchscreen. I needed to grab a remote control out of my armrest to control it. How old fashioned. Why did KLM stay the early 2000’s? After getting an understanding of the system and learning that the buttons need to be pressed really hard to work, I got very disappointed about the available movies. I have not seen such a bad and small collection in years. But this must be a problem of the old entertainment system… So I finally I found a movie I was willing to watch. Only to realize that the headphone output of Seat 37J had a loose contact and a naughty beep on it, like there was something wrong with the potential (–> service advice note for KLM!). So I decided to shut down the system and use my own entertainment system. As a frequent traveller, you are prepared for something like this. But if I had not my own device with me, it would have been a tragedy. Naturally this old entertainment system did also not supply a USB port to charge my phone. But also for this I was prepared with a power pack. And now you’re wondering why my hand luggage is so heavy. By the way from my next travel on, there will also be a fresh set of clothes. I learned my lessons from Air France. As always the crew did it’s best to make us the passengers happy.
We arrived on time in Amsterdam even we drove around 15 minutes on the tarmac. At least the captain had fun when he mentioned, that the runway will be between Shanghai and Amsterdam. Arrived at the airport, there was a 30 minutes journey to the new gate for the flight to Zurich.
Boarding time had already passed for a few minutes, when the ground crew told us to change to another gate, due to technical problems of the airplane. My thoughts were just that this can not be true. Instead of boarding the plane by a finger dock, we got a sightseeing bus ride to the tarmac were the replacement airplane was waiting. We entered the plain and when the flight attendant started to close all the overhead lockers, I asked her if the boarding was complete and I could change to the seats on the emergency exit one row before me, since they were empty. Her answer shocked me. She told me that this were preferred seats and you could only sit there if you pay for it. I replied to her if safety or economics are more important, since there would be nobody to operate the emergency exit door. She froze and I could see that she became aware of the meaning of my statement. But only after she asked the chief purser, I was allowed to change seats. Dear management of KLM: Selling emergency seats for profit is understandable, but how can you make sure that people will be there to operate the doors in an emergency? Above you can see how the seats looked during the flight.
The flight itself was unspectacular. Positive to mention was the captain who told us before we started what the reason for the change of the airplane was. This was for me very professional. We landed with a bit of delay in Zurich and with this I could close my one-week journey.
Almost. After I landed, I saw the reply from Air France about my compensation and the lost money for the preferred seat. A standard answer declining everything because there were extraordinary circumstances. I will not accept this and will fight for my rights. I don’t think a occupied finger dock is an extraordinary circumstance. I always got my rights until now. Even with Easyjet! So let’s put down the coating…
.over-and-out















Neueste Kommentare