Lange hat die Verwendung eines wirklichen XML-Filters wenig Sinn gemacht. Zu aufwändig war es und das gleiche Resultat hat man mit einem einfachen Textfilter auch hinbekommen.
Jetzt hat sich das Ganze aber geändert. Neu kann Studio auch die maximale Länge eines Strings überwachen. Das bedeutet, dass der Softwareentwickler in seiner Umgebung eingeben kann, wieviel Platz es im Dialog hat und diese Information dem XML mitgeben. Und diese Information wird in Studio nun ausgewertet und überwacht. Deshalb sind die Zeiten vorbei, wo die Erstübersetzung nochmals an den Übersetzer musste, weil diese unmöglich im Dialog oder Menüfenster Platz hatte.
Da ich die Erfahrung gemacht habe, dass SDL keinen Filter von grundauf kostenlos erstellt, sondern dies nur über den überteuerten Professional Service anbietet, biete ich hier die kostenlose Anleitung, wie vorzugehen ist.
Ich zeige die Einstellungen in SDL WorldServer. In SDL Studio ist dies gleich, teilweise sehen die Fenster einfach unterschiedlich aus. Ich habe es nur soweit dokumentiert, wie ich es selbst benötige, um einen weiteren Filter konfigurieren zu können.
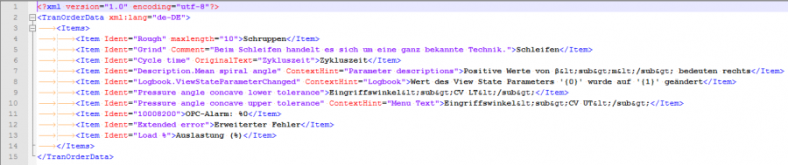
Der Aufbau der XML-Datei
 (1) Der obligate Header
(1) Der obligate Header
(2) Das Rootelement, das der Erkennung der XML-Datei dient und auch gleich den Sprachschlüssel der Quelldatei beinhaltet. Dieser Sprachschlüssel wird von Studio dann in die Zielsprache geändert.
(3) Medaten wie Ident=“ “ oder ContextHint=“ „, welche ausgeblendet werden
(4) maxlength limitiert die Zeichenzahl im Zieltextsegment
(5) Der eigentlich zu übersetzende Text
Filter in WorldServer
Der neue Filter ist vom Typ: Custom XML Studio File Type
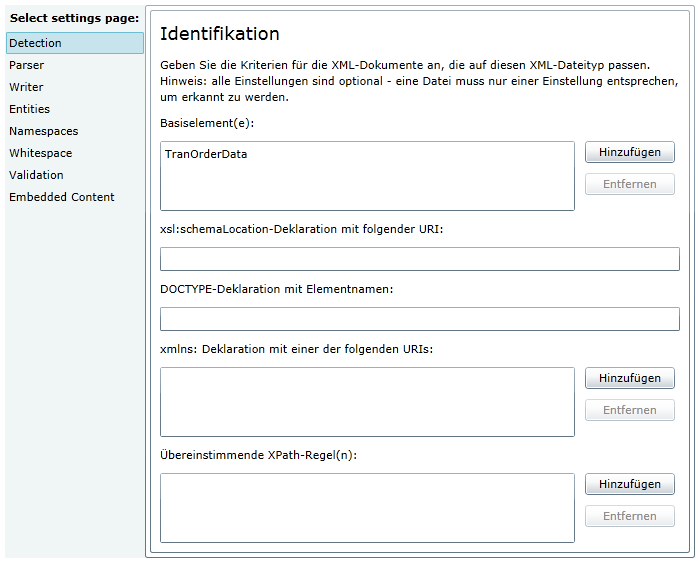
Das Basiselement ist das Element, mit dem ein Parser das XML identifizieren kann. Leider ist diese Funktion bei WorldServer 10.4.2 noch nicht implementiert. In Studio funktioniert es und man kann mehrere MIME-Typen mit *.xml angelegen. Bei WorldServer geht dies nicht und bedeutet, dass pro XML-Typ ein anderes Dateiformat gewählt werden muss.
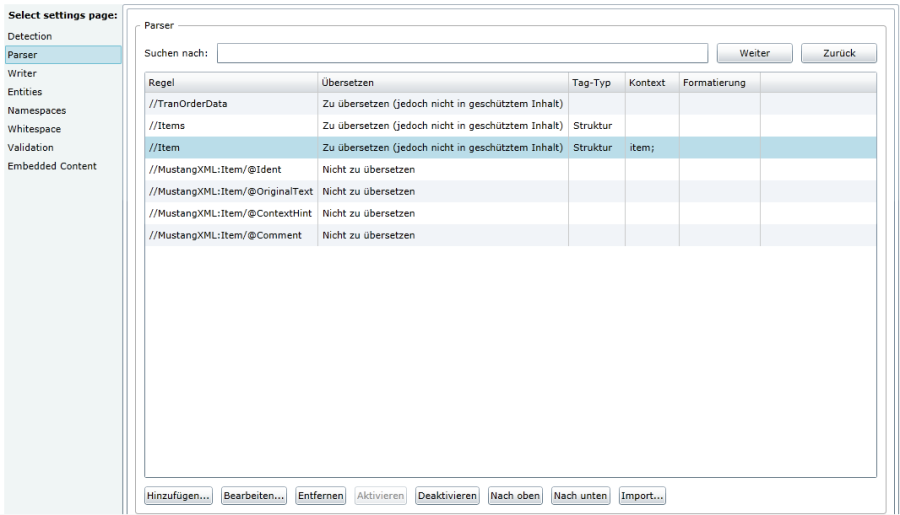
Im Reiter «Parser» stehen alle Regeln, nach denen der zu übersetzende Text und Metadaten gefiltert werden.

Die ersten drei geben die Struktur an und die letzten vier Element die Metadaten
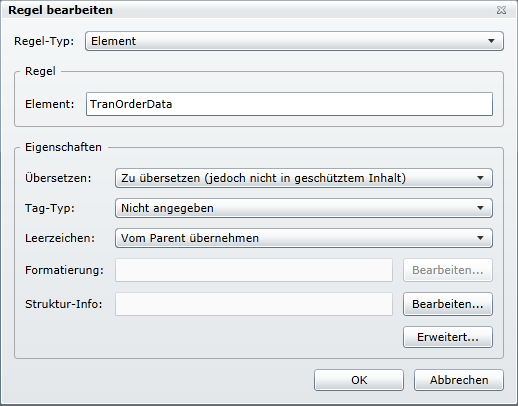
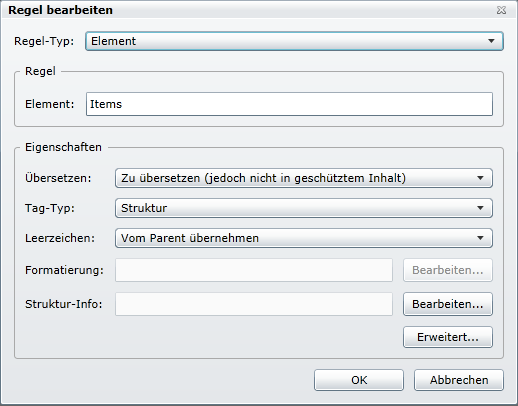
Im Element «Item» ist das Hauptelement mit den Inhalten drin.
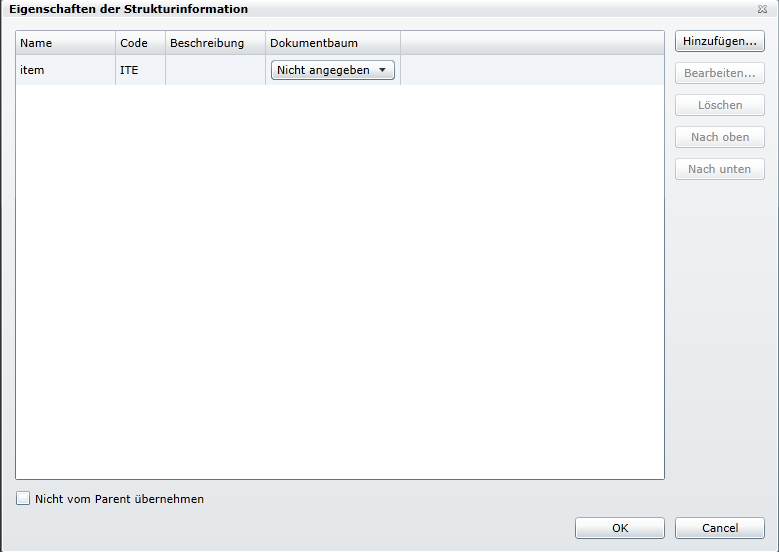
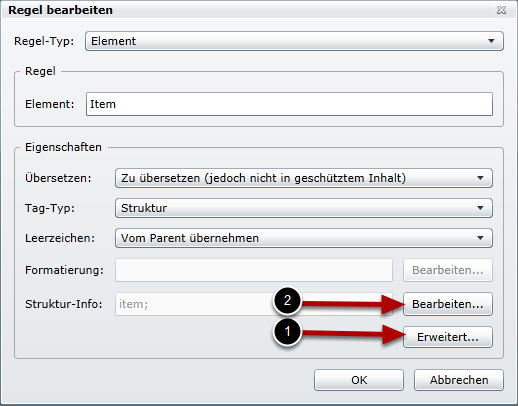
(1) Beim Anklicken von [Bearbeiten…] bei Struktur-Info wird der Dialog für die «Eigenschaften der Strukturinformation» angezeigt.
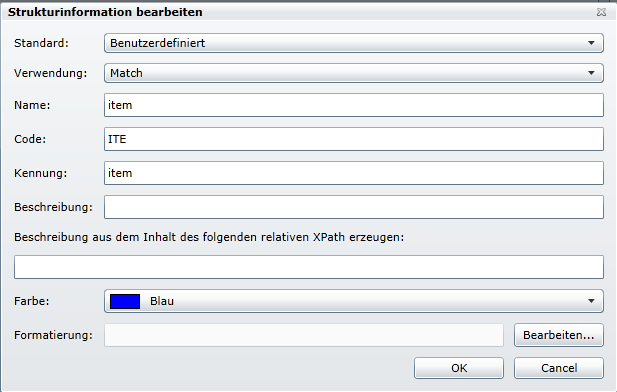
Diese muss wie folgt angelegt werden.
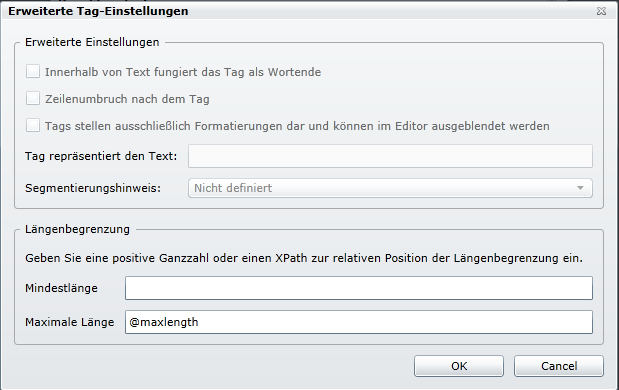
(2) Unter «Regel bearbeiten» [Erweitert…] anklicken. Dort muss noch das Element für die maximale Länge definiert werden. In diesem Fall ist es @maxlength.
Zusatzinfo: «maxlenght=“0″» läuft ohne Fehlermeldung durch den Parser, aber in Studio wird dann eine Längenbeschränkung von 0 angezeigt. Deshalb sollte in diesem Fall «maxlength» gar nicht angegeben werden.
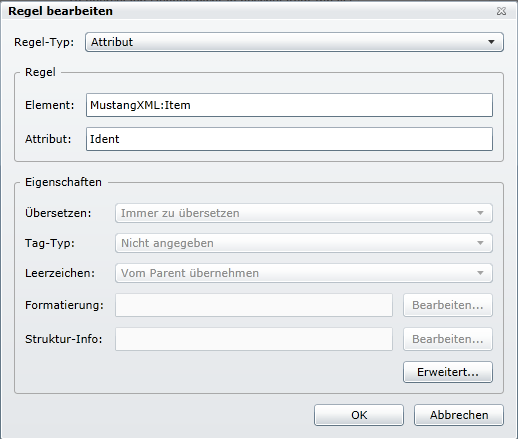
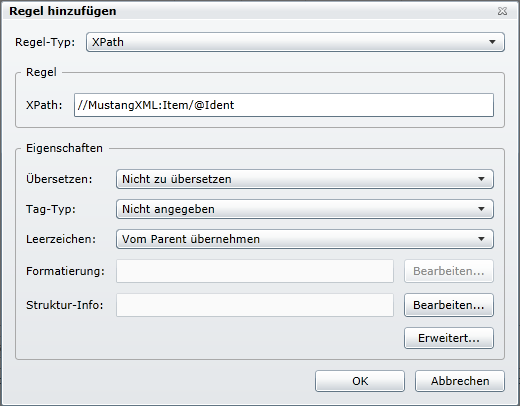
Als letztes sind noch die Attribute zu kennzeichnen, welche nicht übersetzt werden. Leider können diese nicht als Attribut und „Nicht zu übersetzen“ angelegt werden. Es muss ein Umweg über die Erfassung als XPath erfolgen. Ich nehme an, dass dies ein Bug von SDL WorldServer ist, sonst kann ich mir einen solchen Blödsinn nicht erklären.
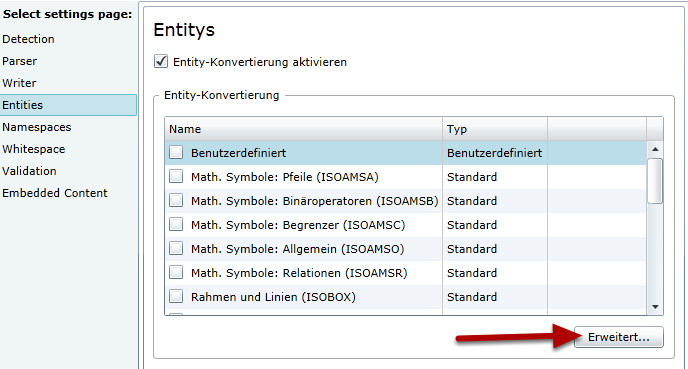
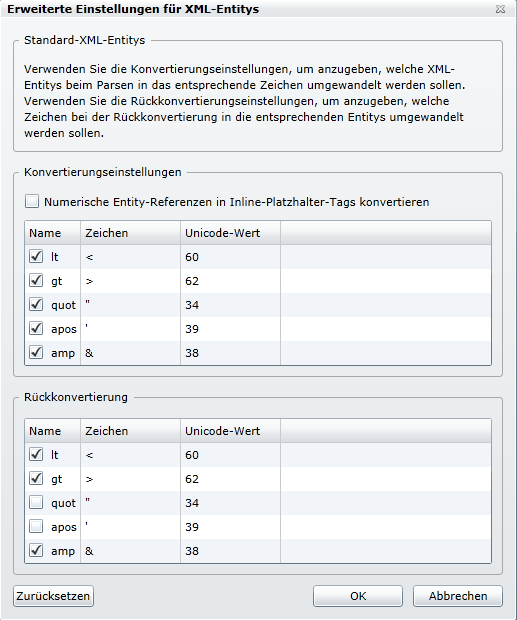
Hier die Entitys, welche umgewandelt werden sollen. Dies betrifft aber nur den zu übersetzenden Text.
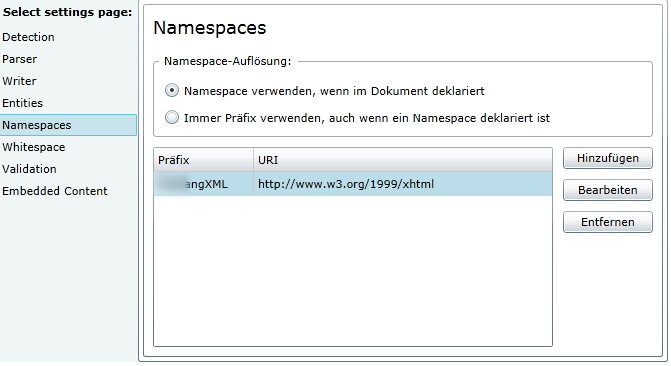
Beliebigen Präfix wählen und die URL von w3 eingeben.
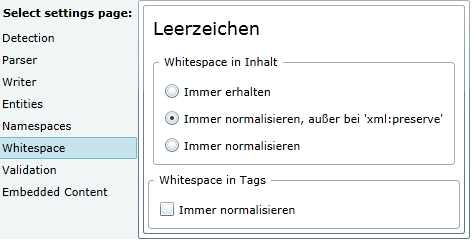
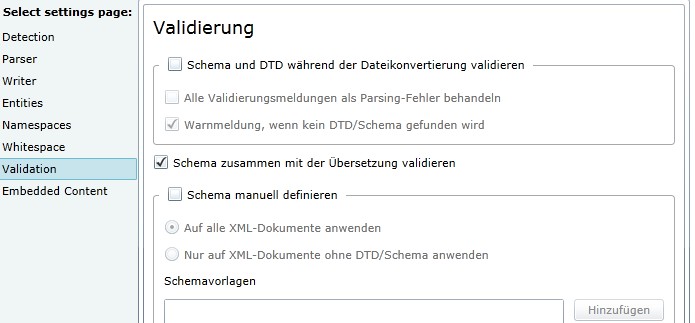
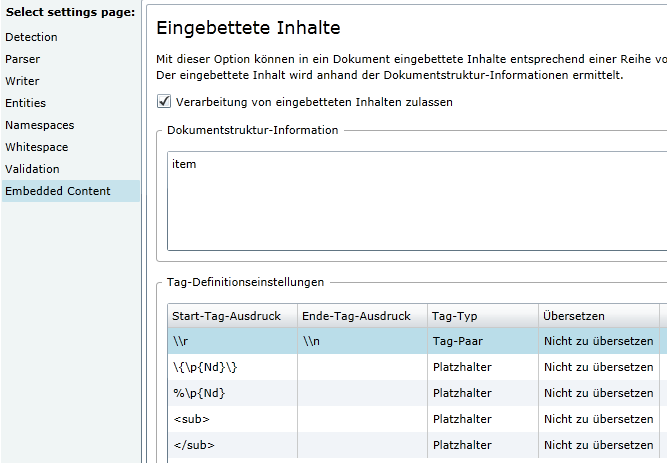
Im «Embedded Content» können RegEx-Filter konfiguriert werden, um Platzhalter und sonstige Ausdrücke zu sperren.
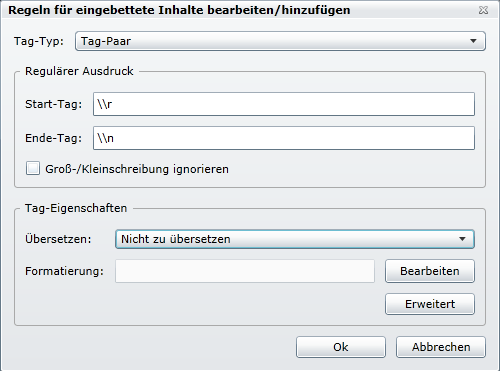
Man unterscheidet zwischen Tag-Paaren. Also alles was zwischen diesen Tag liegt, wird für die Übersetzung gesperrt.
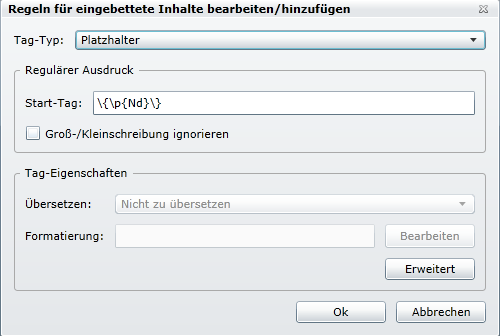
Und Platzhaltern, welche einen Teil/eine Stelle im Text definieren. In der Regel sind dies Variablen.
Zum Schluss noch etwas…
Auf ein weiteres Problem muss man auch noch achten. Es geht um die Verarbeitung mehrerer XML-Filter. SDL Studio kann anhand des Rootelementes selbst entscheiden, zu welchem Filter eine XML-Datei passt. SDL WorldServer kann dies nicht, obwohl diese Information im Filter definiert werden muss. Nun, wenn diese Information nicht ausgewertet wird, wieso muss man diese dann erfassen?
Das Resultat ist aber, dass SDL WorldServer in der aktuellen Version 10.4.4 nur eine einzige XML-Datei mit der Dateierweiterung .xml verarbeiten kann. Eine weitere XML-Datei muss eine andere Dateierweiterung haben oder zu einer anderen Filtergruppe gehören, mit dem Resultat, das der Benutzer dann den richtigen Filter auswählen müsste… Was mich verärgert, ist der Fakt, dass Studio das Problem nicht hat und mehrere XML-Dateien anhand des Rootelementes unterscheiden kann. Man beachte auch, dass ich Studio ab 99€ bekomme und WorldServer etwa das tausendfache kostet. Ein Lösung für WorldServer 11.0 wurde mir auch nicht zugesichert.
.over-and-out
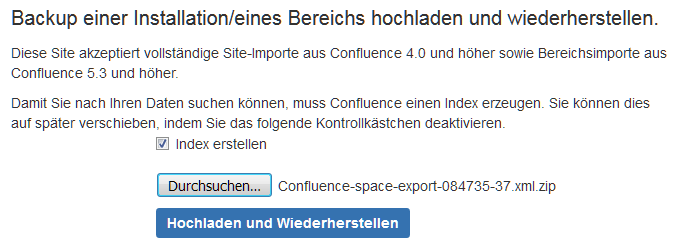
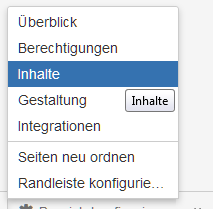 –> Seite «Bereich konfigurieren» öffnet sich.
–> Seite «Bereich konfigurieren» öffnet sich.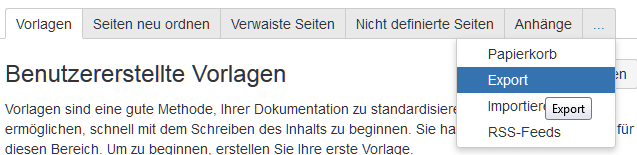 –> Seite «Export» öffnet sich.
–> Seite «Export» öffnet sich.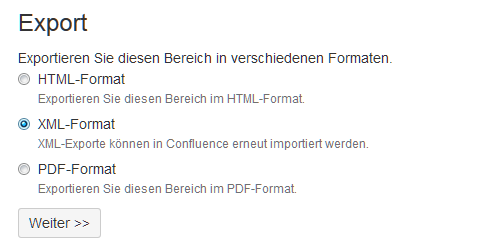
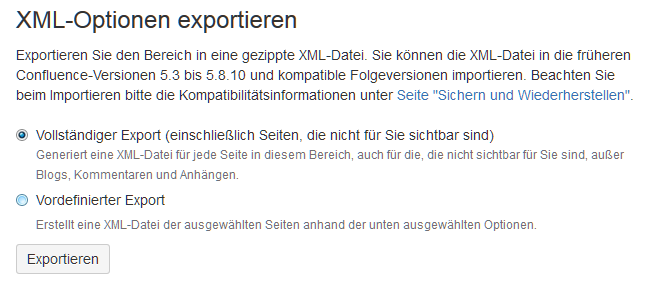 –> Export startet.
–> Export startet.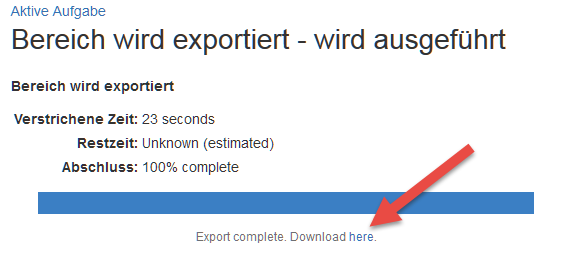 –> Die zip-Datei wird auf dem Rechner gespeichert.
–> Die zip-Datei wird auf dem Rechner gespeichert. –> Seite «Administatorzugriff» öffnet sich. Dort das Admin-Passwort eingeben.
–> Seite «Administatorzugriff» öffnet sich. Dort das Admin-Passwort eingeben.

 Ich bin schon seit bald 20 Jahren in der Technischen Dokumentation tätig. Persönlich habe ich bis heute noch nie DITA in einem Projekt verwendet und schon vor Jahren habe ich es als Hype der Amerikaner und Dienstleister/Toolanbieter abgestempelt. Hinzu kommt, dass viele Länder ausserhalb des deutschsprachigen Raumes im Bereich der Technischen Dokumentation unterentwickelt sind. Und wie sagt man so schön: «Bei den Blinden ist der Einäugige ein König!» Auch in den USA gibt es noch viele Firmen (ausserhalb der Mega-Konzerne), die genauso wenig ein Ahnung von strukturierter Technischer Dokumentation haben, wie es in Deutschland in der Regel ein Kleinbetrieb auf dem Land hat. Garagenfirmen sind nicht immer cool ;-).
Ich bin schon seit bald 20 Jahren in der Technischen Dokumentation tätig. Persönlich habe ich bis heute noch nie DITA in einem Projekt verwendet und schon vor Jahren habe ich es als Hype der Amerikaner und Dienstleister/Toolanbieter abgestempelt. Hinzu kommt, dass viele Länder ausserhalb des deutschsprachigen Raumes im Bereich der Technischen Dokumentation unterentwickelt sind. Und wie sagt man so schön: «Bei den Blinden ist der Einäugige ein König!» Auch in den USA gibt es noch viele Firmen (ausserhalb der Mega-Konzerne), die genauso wenig ein Ahnung von strukturierter Technischer Dokumentation haben, wie es in Deutschland in der Regel ein Kleinbetrieb auf dem Land hat. Garagenfirmen sind nicht immer cool ;-).
Neueste Kommentare