What a hassle; every day/week, I needed to check, if I could download my favorite series from http://serienjunkies.org. Waiting for some good souls to add them.
And I thought for a long time, how great it would be, if this could be done automatically. And there is a solution. Thanks Beni!
It’s not completely free, but today I still have expenses. To download the files from serienjunkies, I needed an account from uploaded.net which costed 70€ per year.
The new solution works with the Usenet and here you need an account. This cost me 95.40 US$ a year. So, it’s a little bit more expensive than the other solution, but it also comes with a VPN service which even works on my iOS devices.
What is Usenet? Usenet intimidates many people, if they have even heard of it. It has always been known the first rule of Usenet is you don’t talk about Usenet, but the cats out of the bag now and it’s time to get involved. Usenet is an online service that is in a sense a massive message board system. There are thousands of different message boards discussing a vast array of topics on Usenet and also boards that supports binary (file) posts. This means there are EXABYTES of data available on Usenet, with the content base growing by Terabytes A DAY! Even with all this Usenet has never really garnered mainstream attention the way that other file sharing services have, and that is in a way a good thing; but I’m going to make you want into the club! This definition and more explanation you can find here: http://www.totalhtpc.com/TheCompleteUsenetGuide.pdf. But don’t buy the services they offer there!
What is required?
- A Usenet account. I’ve chosen “usenetserver.com”, which costs 95 US$ a year.
- A Indexer account: I’ve chosen “nzbgeek.info”, which costs 30 US$ for lifetime pass.
- Synology: Add in the packet center http://packages.synocommunity.com/ as a source.
- Synology: Install “NZBget” from SynoCommunity
- Synology: Install “Sonarr” from SynoCommunity
There will also some additional packages installed, just let it happen. If Sonarr doesn’t want to start after installation, restart the Synology. I helped in my case.
The Indexer account is required, because as it name says it indexes the Usenet for your content.
What is Sonarr? It is designed to organize your episode files on disk, for consumption by Plex. It also talks to your download client (Usenet and torrents) and their corresponding indexers to watch for episodes you’re missing to send them to your download client for download. But we don’t want to use torrents, because those downloads can be tracked…
Sonarr is the main app which does all the work. The only thing left is to set it up and also to set up NZBget.
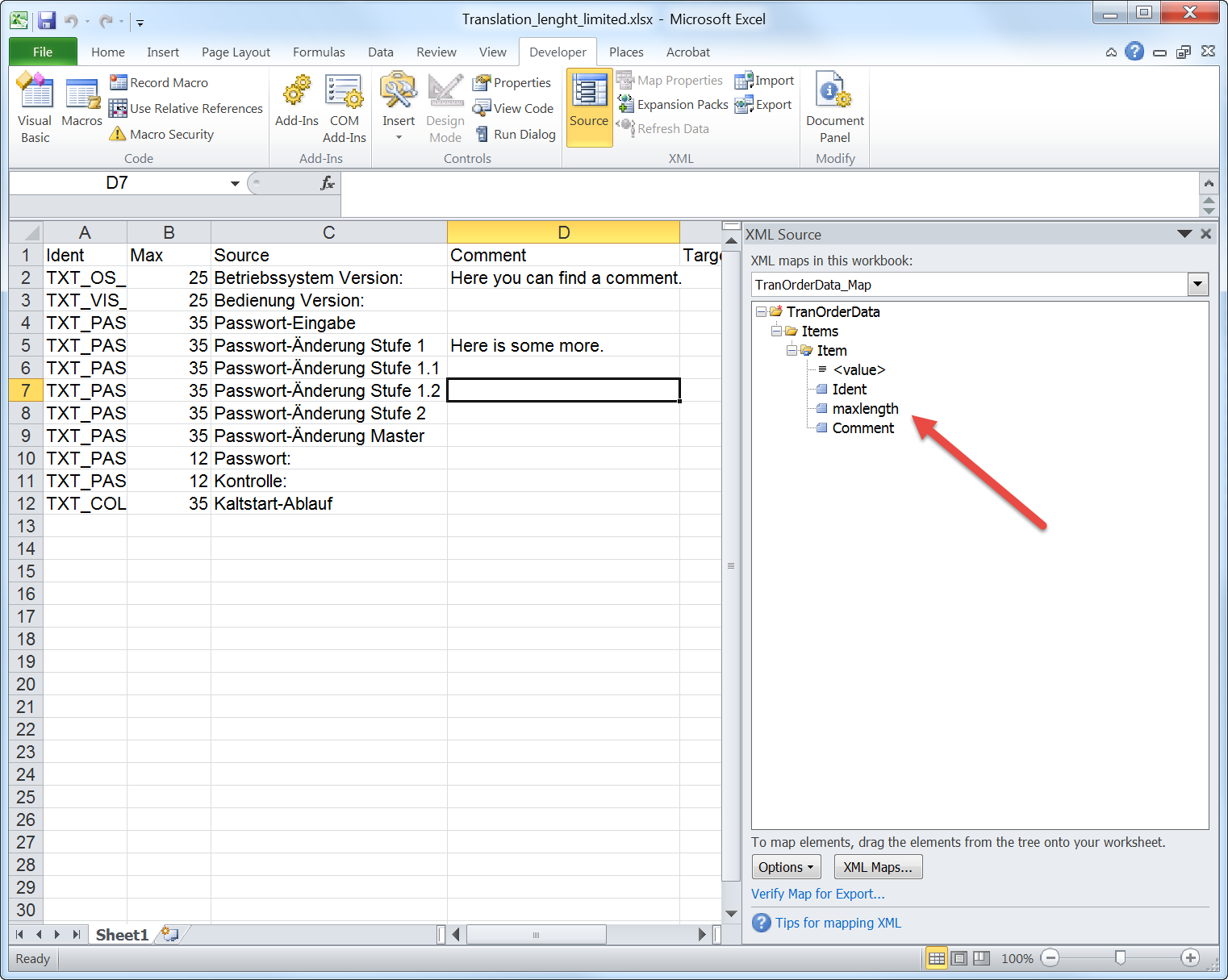
Open Sonarr in your browser. And go to “Settings”.
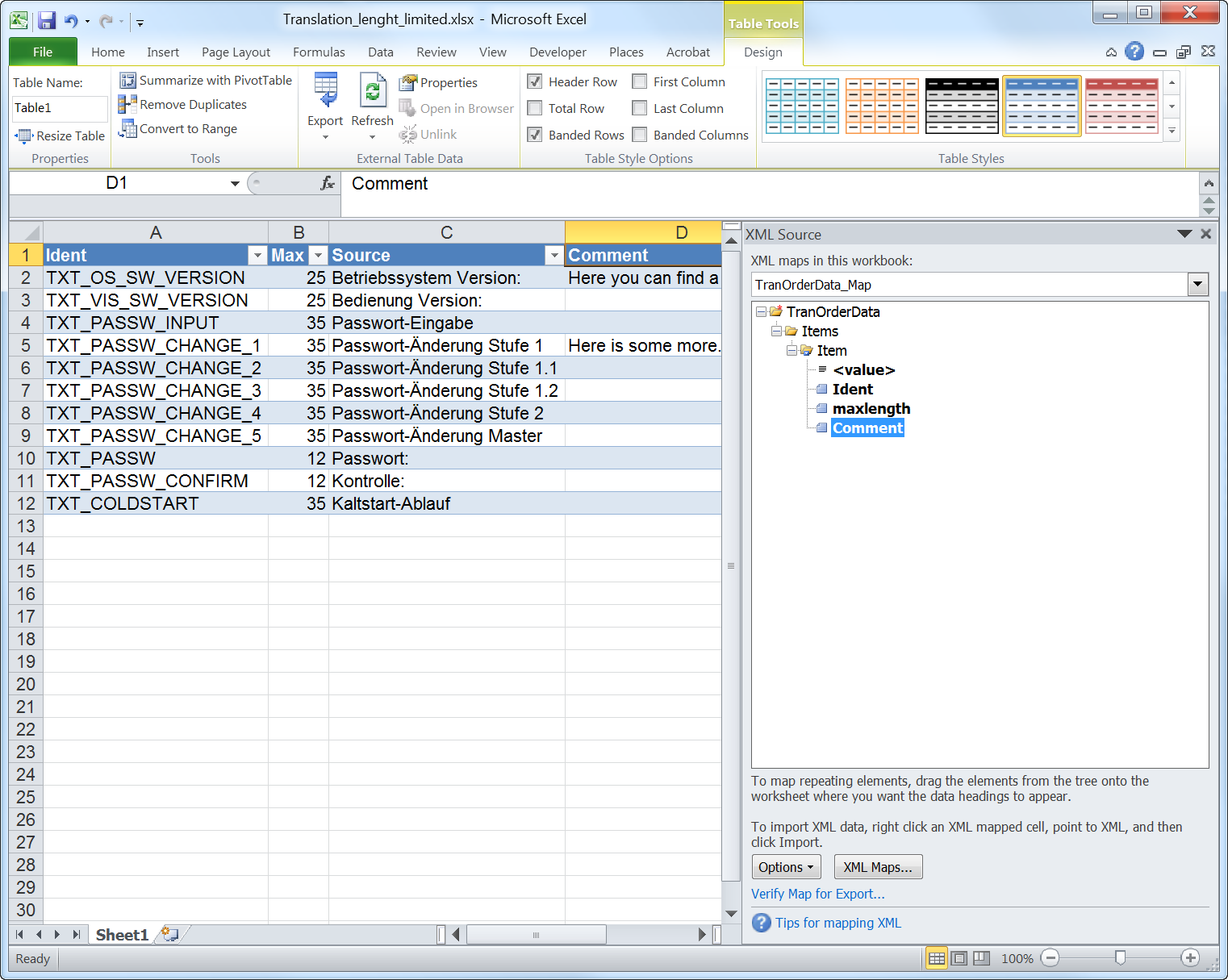
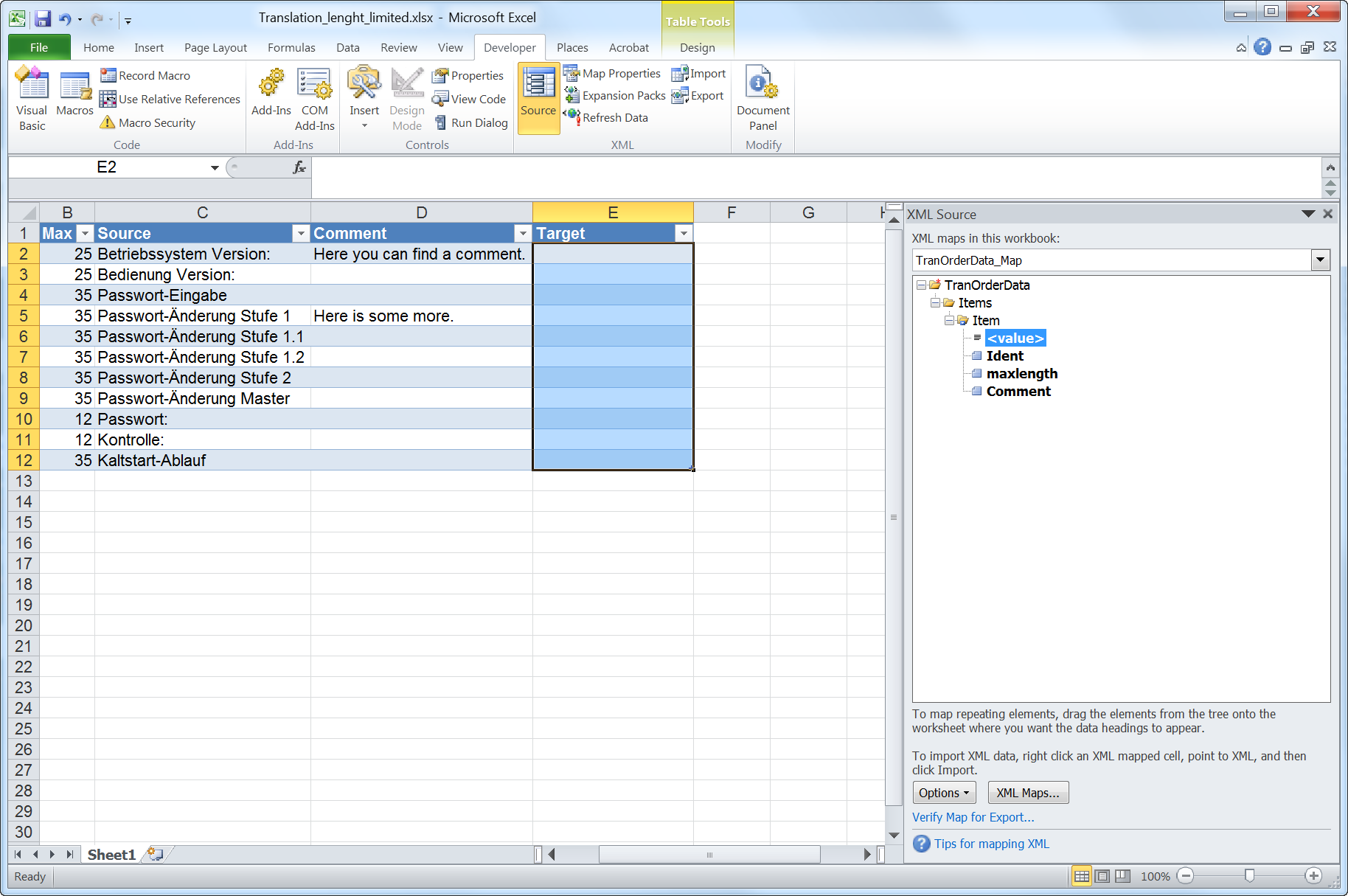
In “Settings” you can go through all submenus once it’s running. First you need to set up the “Indexers”, the “Download client” and the “Connect.
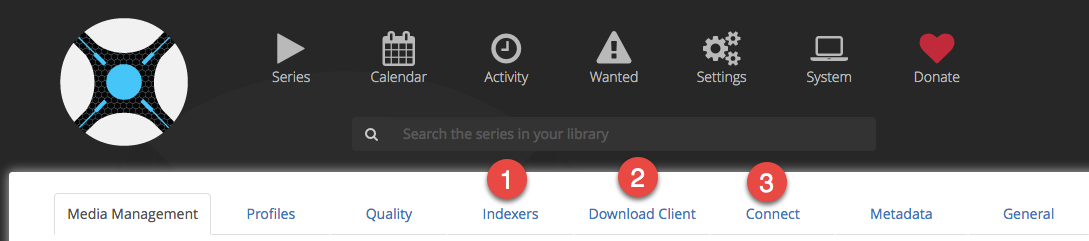
Indexers: Click on the plus and choose “Newznab” with the preset for NZBgeek.
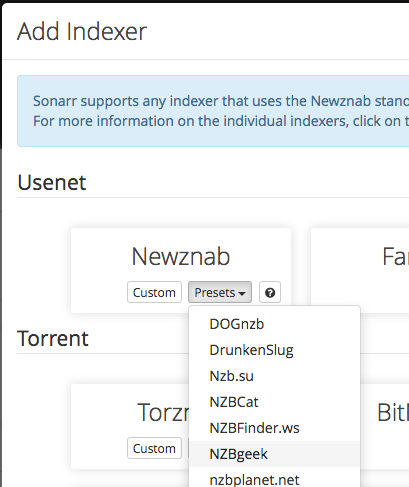
In the dialog for the settings, add the API key, which you can find in your nzbgeek.info account. This API key you only get, when you have the “Forever Geek Pass” status which costs 30 US$. Always “Test” the connection! Btw: Shown is not a valid key! 😉
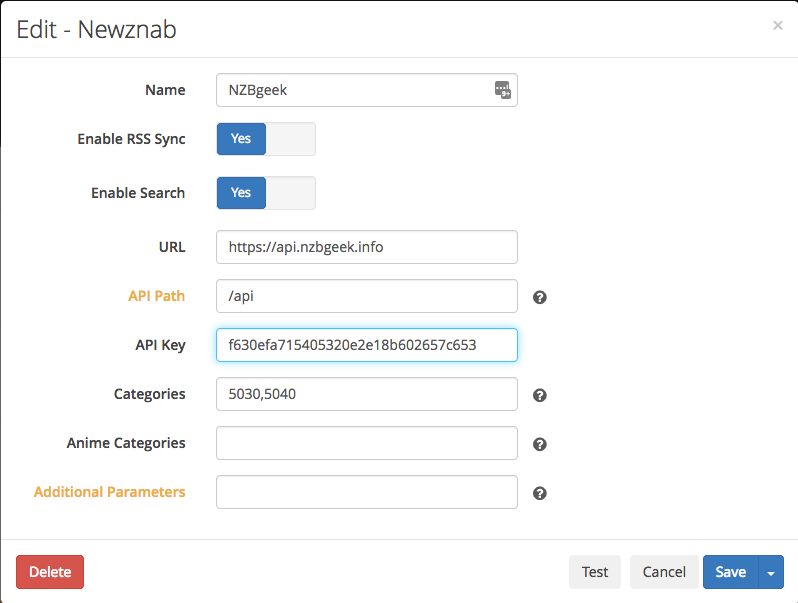
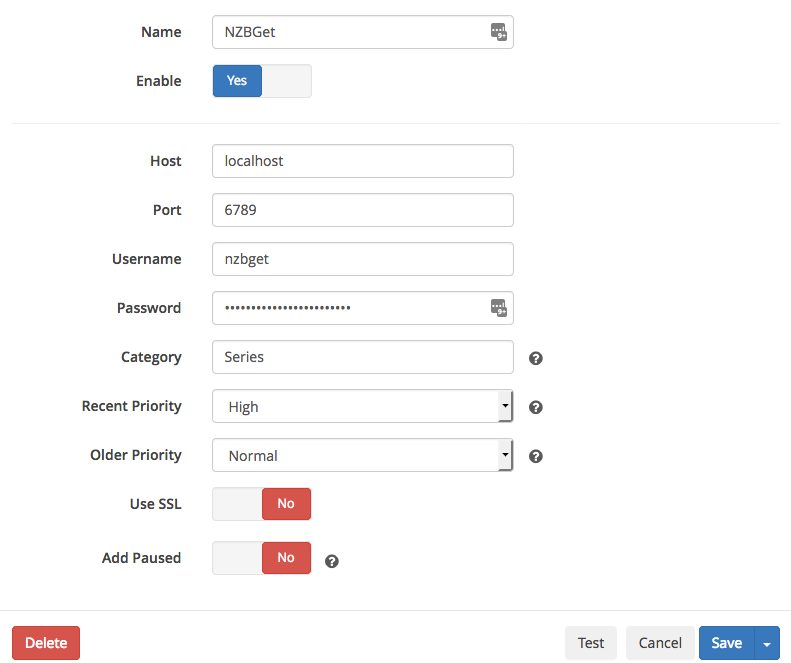
Download Client: Add “NZBget” and fill out the information in the dialog. The username/password are the ones you have chosen when you installed NZBget on your Synology. Always “Test” the connection!
Connect: Add “Plex Media Server” and fill out the information in the dialog. The username/password are the ones you need to connect to your Plex account. Always “Test” the connection!
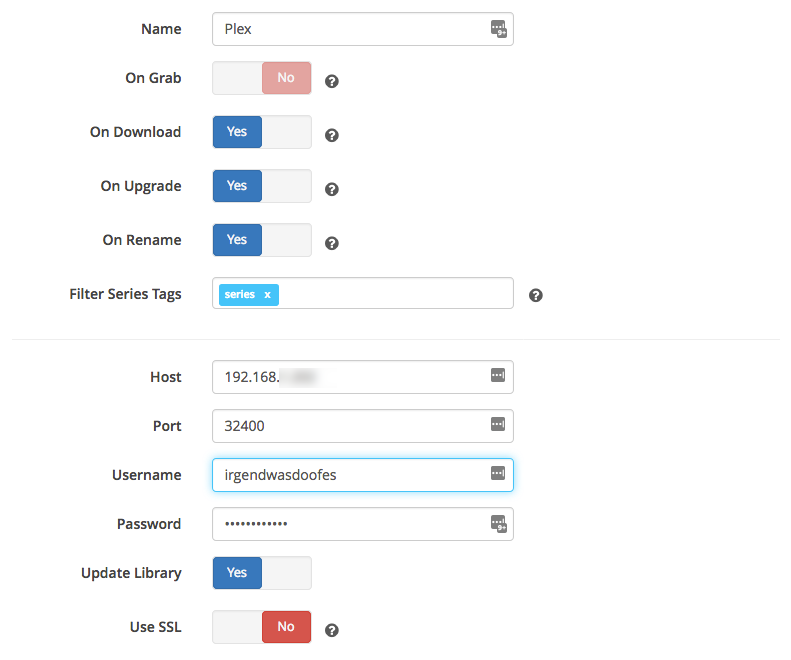
The settings in Sonarr are done.
Let’s go to NZBget.
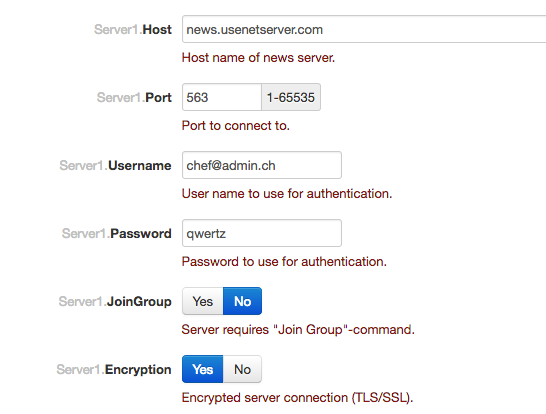
Open NZBget in your browser. Go to “Settings” and there to “NEWS-SERVERS”. Enter the information you’re your usenetserver.com account. Open this port in your Firewall! Click on “Safe all changes”. That’s it.
Go back to Sonarr.
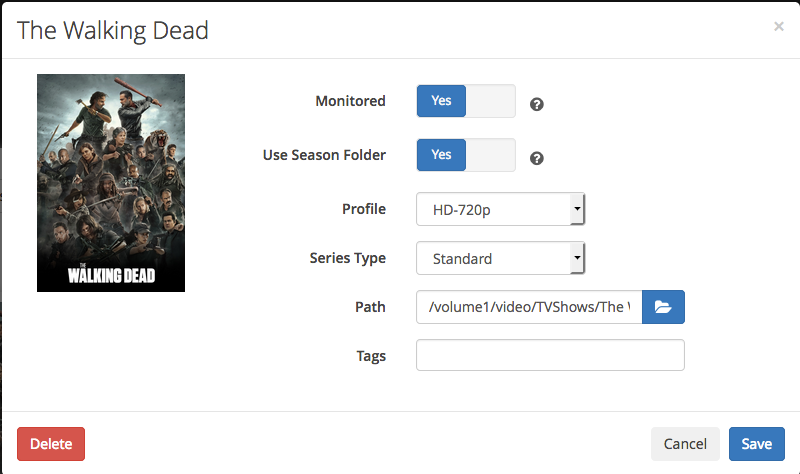
When you click on “Series” then it is empty. Click on “+Add Series” to add them. Important is to set it to “Monitored” so Sonarr downloads new episodes automatically. Set the correct path to your series on your Synology.
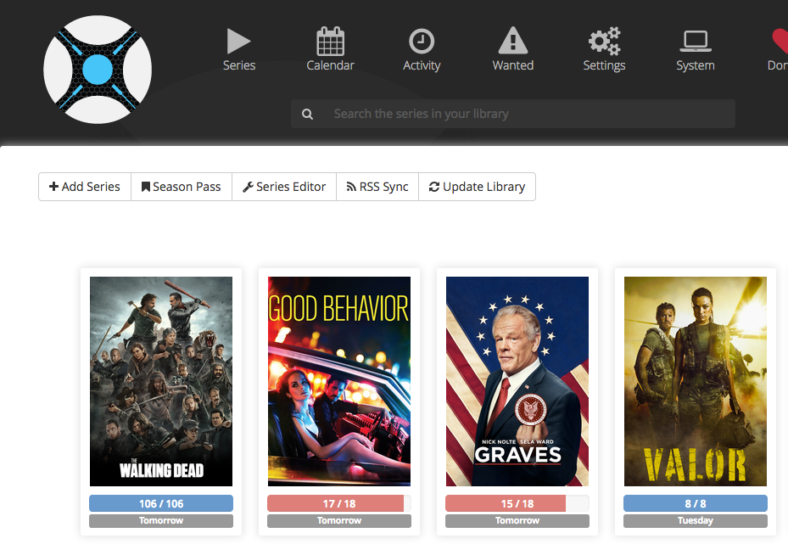
Sonarr then checks with your Plex server if you have already some episodes and shows their status. It should show you something like this. The color codes are described at the bottom of the page.
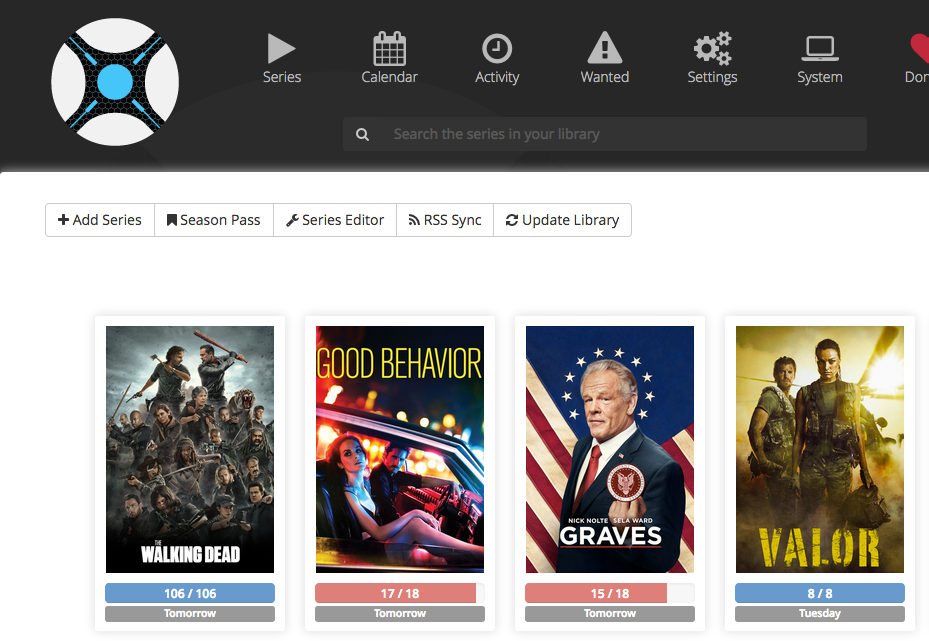
It even shows you a “Calendar” with your series and the download status.
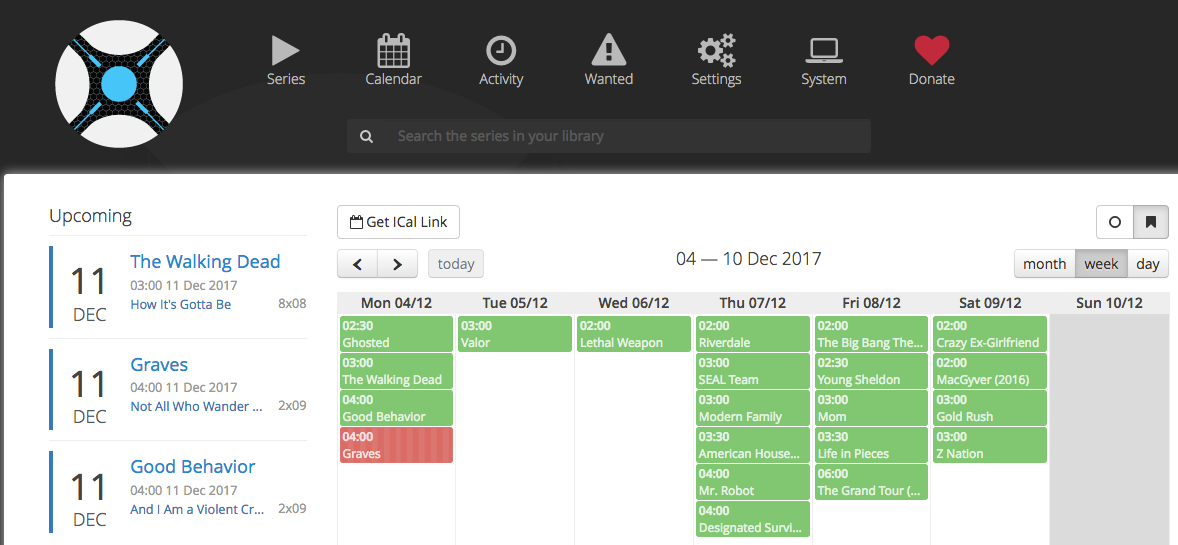
When you go to the “Wanted” section, then all missing episodes are shown. Click on “Search All Missing”, if you want to manually force Sonarr to look for them. Once they are found, it will be sent to NZBget and shown in “Activity”.
That’s it, have fun with your series.
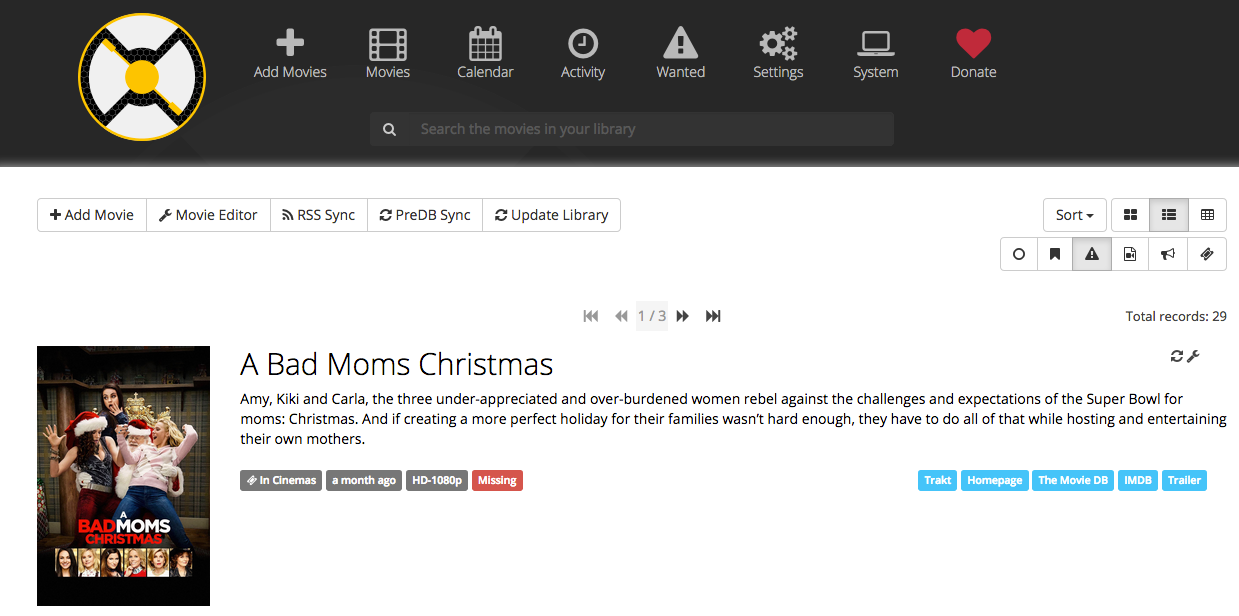
By the way: If you want to do something similar with movies, then use Radarr. It’s a Sonarr fork which handles movies. So, you can have Radarr looking for you movies even month before they are available. Once they are available, you will get them first. To further extend the automation, I connected it to my “CouchPotato” (also on my Plex) and “Trak list” on the web. Just google yourself into this. The settings are very similar to Sonarr.











Neueste Kommentare